
生物多様性ビッグデータ①:その危機?
私は、”生物多様性ビッグデータ”という言い方を(あえてよく)するのですが、世の中で言われているような”ビッグデータ”とは、少し違うのかな?と思っています。
まず、生物多様性のデータ規模は(かなり)小さいです。
これは、生物多様性情報の多くが、人力で収集されているためです。生態学者が野外調査で生物の分布を記録したり、分類学者が種を分類して記載したり等など。
生物多様性データは、ネットワーク化された情報基盤(ICTなど)で自動で機械的に収集されるデータとは、全く異なるのです。
研究者が手作業で集めるのですから、なかなかビッグなデータになりませんし、研究者がデータ収集するのをやめたら、それで終わりです。データ自体も雲散霧散して、消失することすらあります。
つまり、生物多様性情報は、地道な「基礎研究の歴史」で集積された知見なのです。
生物多様性のデータの規模や、その収集が人手に依存している点では、ビッグデータというのは大げさかもしれません。しかし、集積の時間スケールは、間違いなくビッグデータと称すべきものです。
基礎研究の歴史は、研究を行う基盤と研究者が揃っていればこそ持続可能です。したがって、研究基盤と研究者層が脆弱になれば、歴史は途絶えますし、データの集積も立ち行かなくなります。
私は、生物多様性ビッグデータの可能性を強調してますが、生物多様性ビッグデータの危機についても、もっと強調したいです。
以下に、興味深いデータを紹介します。
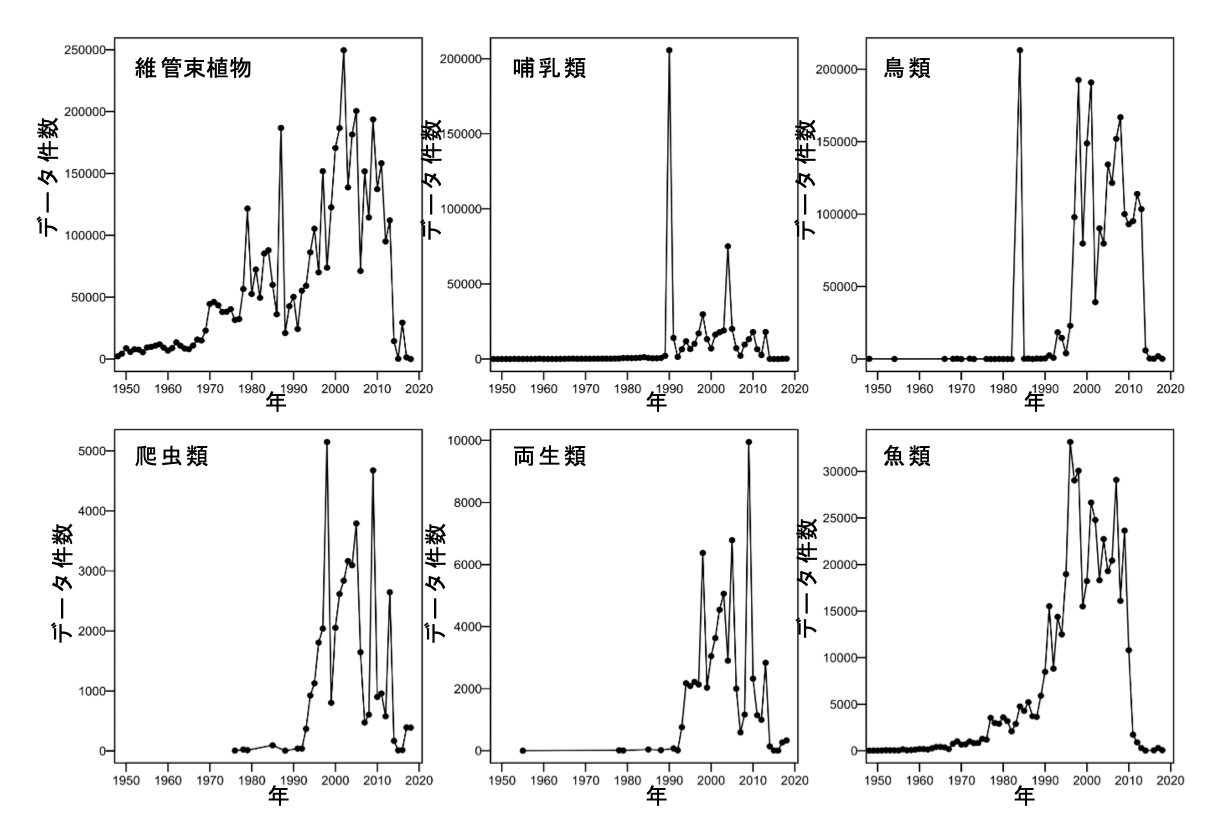
これは、日本の生物種の分布記録が、時系列でどのように集積されてきたのかを示しています。横軸は年代、縦軸は各年代に収集された生物種の分布データの数です。なお、このデータは、科学的分析に耐えうる精度の高いデータにクリーニングされた後のデータ数です。信頼性の低いデータは除いた分布記録数です。なお、現状のデータ整備の完全性が高いのは2013年までに観測されたデータです。2014年以降については、現在もデータ整備中なので、グラフのトレンドは2013年までを見てください。
そして、以下の動画は、植物の分布データ集積の時空間パターンです。
https://www.youtube.com/watch?v=TDVaBtNSAgY
分布記録データの収集は2000年くらいにピークを迎えて、その後、2013年までデータの収集量が停滞しているように見えます。このパターンは、植物、哺乳類、鳥類、爬虫類、両生類、淡水魚類、全ての生物分類群に一貫しています。
日本の生物多様性の情報基盤の整備に、何か起こっているのでしょうか?
https://note.com/thinknature/n/nc2c059eb7192
※本記事のグラフは、環境省の環境研究総合推進費プロジェクト(環境変動に対する生物多様性と生態系サービスの応答を考慮した国土の適応的保全計画)の結果の一部です。