
レッドデータブック:生物多様性ビッグデータで希少種の保全施策を検証する
生物多様性保全を計画するとき、希少種あるいは絶滅危惧種が注目されます。
環境省が選定する日本の絶滅危惧種は合計で3,732種です。
https://www.env.go.jp/nature/kisho/hozen/redlist/index.html
地方自治体もレッドリストを作成しており、地域レベルでも、絶滅危惧種の状況を注視しています。
絶滅リスクを評価する場合、生物種の希少性、つまりレア度が指標になります。種の希少性は、分布している面積や種の個体数で定量します(さらに、分布面積や個体数の増減も定量する必要があります)。しかし、種の分布面積を正確に把握することは、実際には難しく、まして、生物種の総個体数なんて、わかるはずもありません。

分布面積や個体数を正確に把握できるのは、まさに絶滅の崖っぷちにあるような生物で、「もはやここにしかいません!」と断言できるような生物か、膨大な調査を実施して十分なデータを収集した生物くらいです。
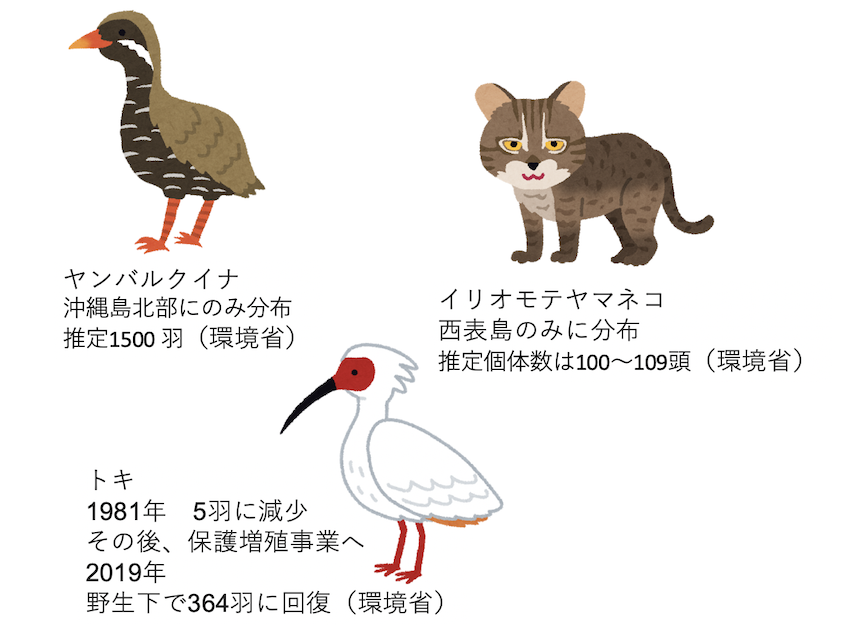
これは、生物多様性情報のショートフォールと呼ばれる問題の一つです(Prestonian shortfall、関連記事の解説を参照)。
しかし、生物多様性情報が不完全な状況にも関わらず、日本のレッドリストはとても良くできています。環境省が国レベルのレッドリストを編纂し、さらに各自治体も地域レベルでレッドリストをまとめて、定期的に絶滅危惧種の現況を調査して、種個体群の増減を定量しようと努力しています。
一方、自治体の絶滅危惧種のリステイングや評価に関わっている現場の方からは、レッドリスト事業が科学から離れているという意見も聞こえてきます。
これは、どういうことかと言うと、絶滅危惧種のリスト化やランクづけが、十分なデータがない状況で、専門家の経験的な議論に基づいて検討されるからです。
実際のところ、専門家の知見にも限界があるのは事実です。
例えば、日本には植物だけでも、5000種以上の植物が分布しています。経験的な知見だけで、5000種を超えるそれぞれの植物種について、絶滅危惧かどうか、さらには、どれくらいの絶滅リスクがあるか(各種の個体群が増えているのか減っているのかを網羅的に)を推論するのは、不可能です。
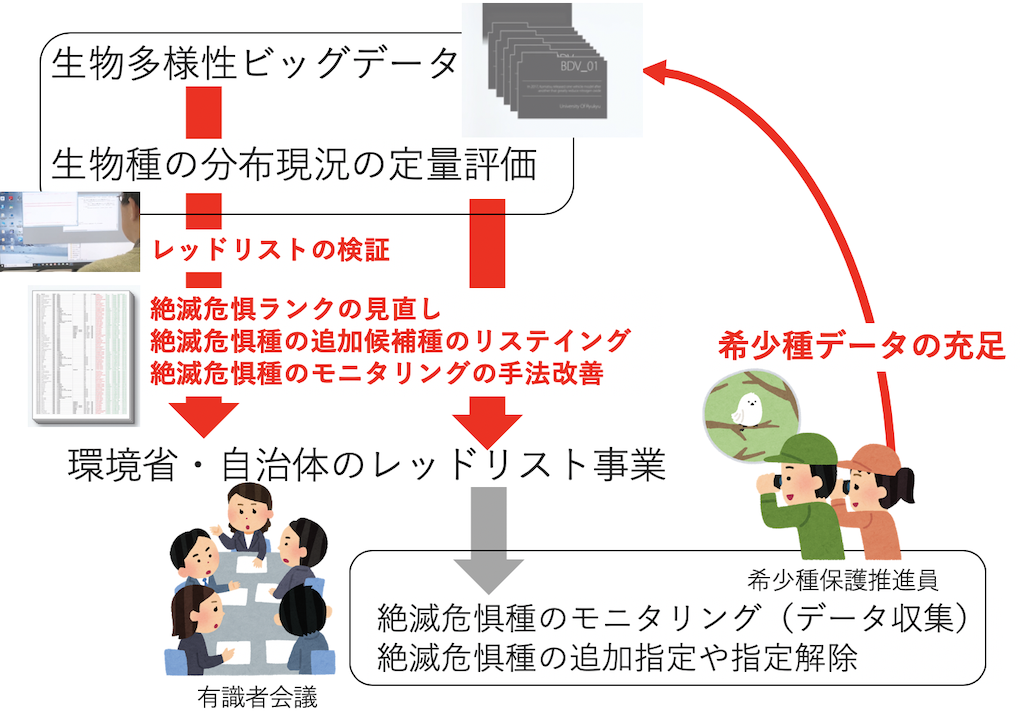
このような知見の限界問題に関して、生物多様性ビッグデータの活用が有効です。今まで知るよしもなかった、希少種の分布面積や個体数を推定できるからです。
例えば下のグラフは、熊本県の保護上重要な野生動植物リスト(レッドリストくまもと)の絶滅危惧種それぞれについて、種の分布面積を推定した結果です。
横軸は、絶滅危惧のランク(カテゴリー)です。絶滅危惧のランクが高いほど(グラフの左のカテゴリーほど)、縦軸に表示した、種の分布メッシュ数が少ない傾向があります(ピンク色の箱の中の横棒が、種分布面積の中央値を示してます)。これは、現状の知見に基づいた絶滅危惧のランク付けが、大まかには妥当であることを示しています。
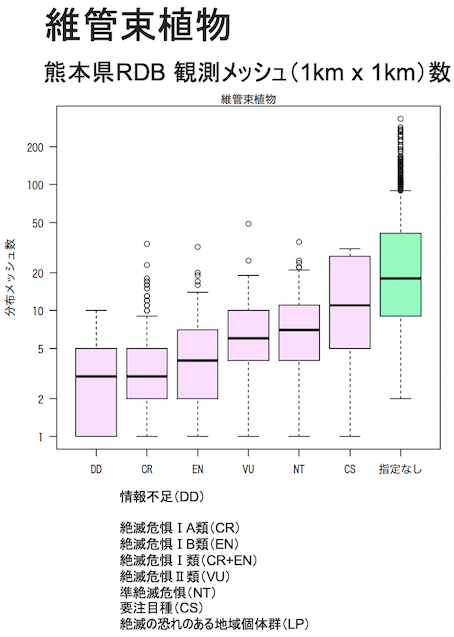
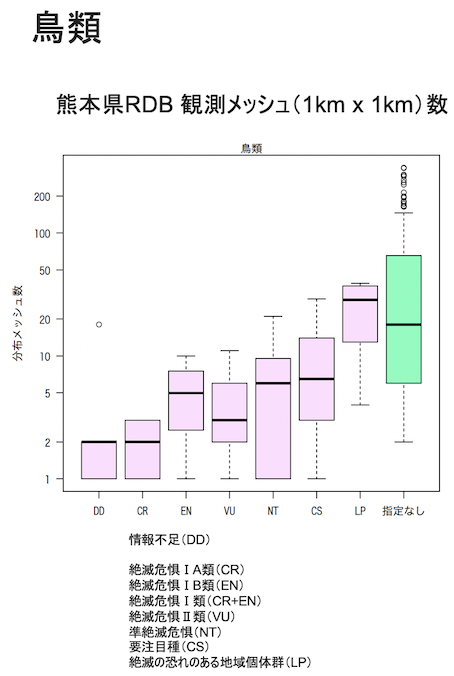
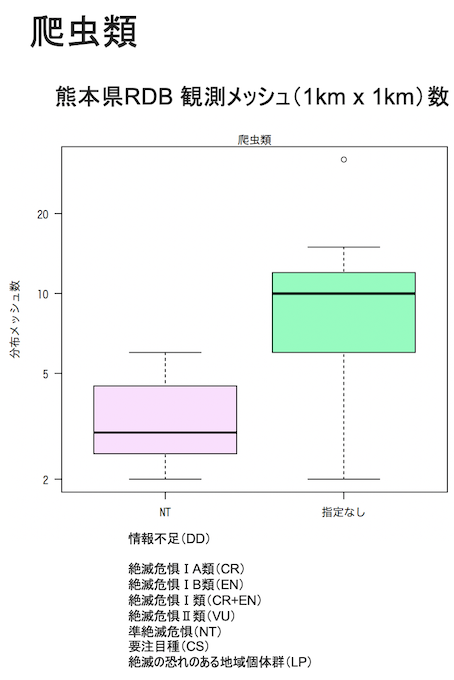
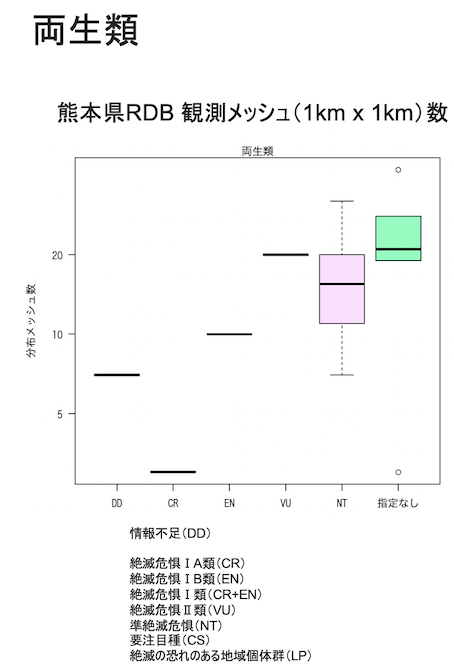
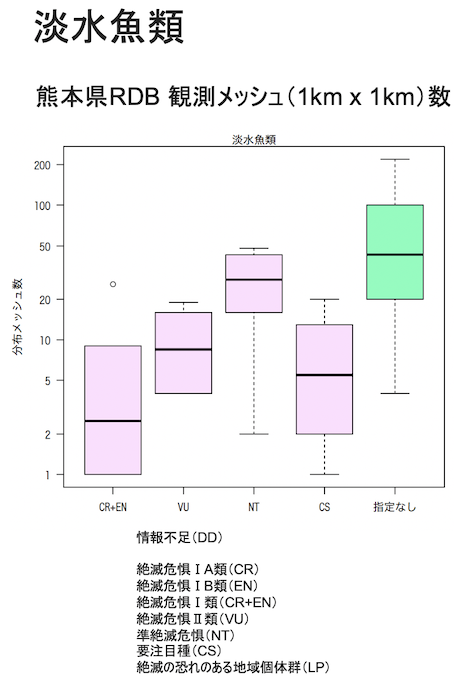
以上のグラフは、箱ひげ図といって、箱の長さからデータ(種分布面積)のバラツキも把握できます。
この点に注意してみると、同じ絶滅危惧カテゴリーの中でも種間で分布面積がとてもバラついていることが、わかります。また、絶滅危惧のカテゴリー間で、分布面積の違いが顕著でないケースもあります。絶滅危惧のリスクが低いとランク付けされた種でも、分布面積がかなり小さいケースも少なくないです。
例えば、淡水魚類を見てみると、要注目種(CS)の分布面積は、絶滅危惧Ⅱ類(VU)や準絶滅危惧(NT)よりも、希少な傾向を示しています。
さらに、全ての生物分類群に共通して、絶滅危惧種に指定されていない種(箱ひげグラフの右の緑色表示の”指定なし”=安心と判定された種)でも、分布面積が小さい希少種(箱の下に伸びたヒゲ)が多くあることがわかります。
つまり、専門家の経験的な知見で見落とされた希少生物が、レッドリストから漏れて、絶滅の危機に瀕している可能性もあるということです。
同時に、分布面積が大きな種が、絶滅危惧種にリスト化されているケースも少なくないです。
このような分析から、レッドリスト種の妥当性を検証することができ、今後、どの種をレッドリストに指定すべきか(指定解除できるか)も検討できます。
熊本県のレッドリストについて、絶滅危惧種に指定されていない種の中から、今後、レッドリストに追加すべき希少種を選定してみました。特に、草本は候補種がとても多く見つかりました。草本の場合、そもそもの種数が膨大ですから、それぞれの草本種について、経験的に絶滅危惧を判定することが困難で、見落とされていた種が多かったのでしょう。
さらに、ビッグデータを活用すると、生物種それぞれの総個体数も推定できる可能性があります。
日本全土に、樹木が何本あるのか、各樹木種が何本あるのか、全て数えあげることはできません。しかし、ビッグデータを活用すれば、種毎の個体数まで把握できる場合もあります。
日本に分布している木本(樹木)の各種の総個体数を推定して、各樹木種の個体数と、絶滅危惧ランクの対応関係を検証した結果が下のグラフです。
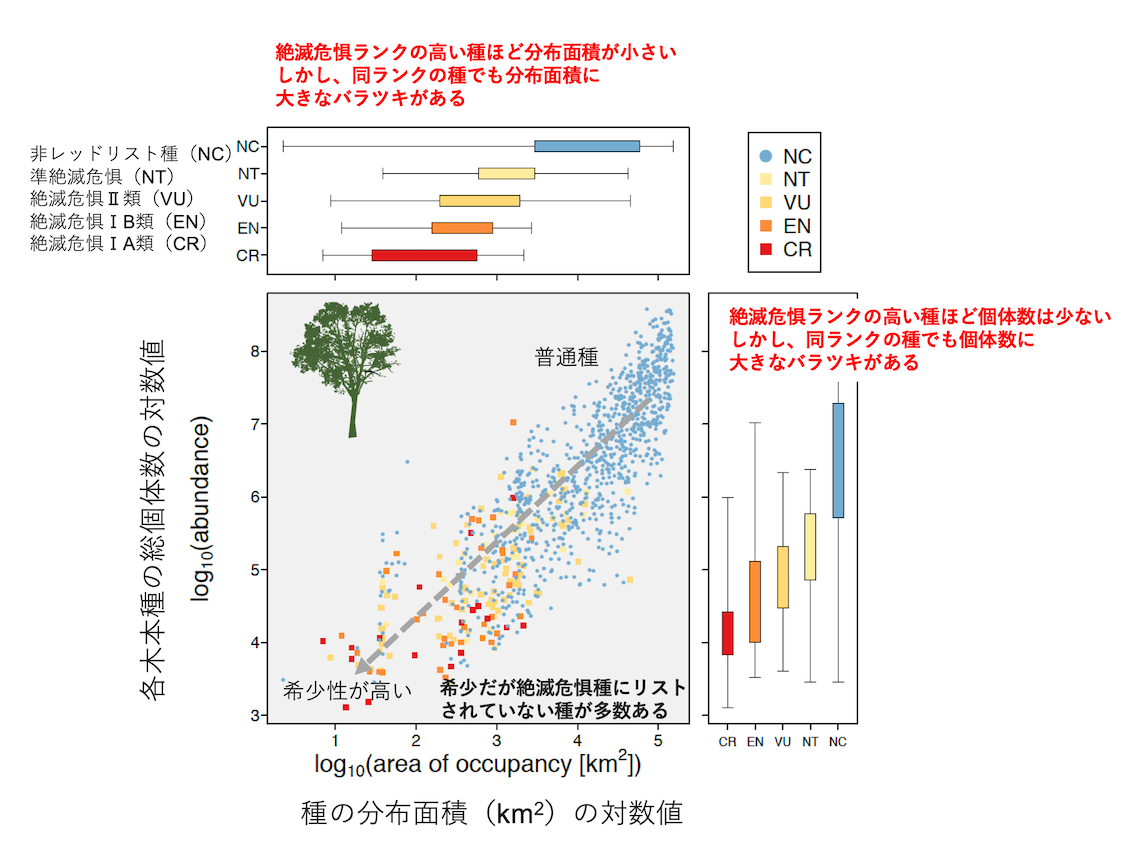
散布図の横軸は樹木種の分布面積で、縦軸は樹木種毎の総個体数です。分布面積が小さくて、総個体数の少ない種ほど希少な樹木種ということになります。グラフの右上は普通種で、グラフ左下になるほど希少種であることを意味します。
それぞれの樹木(シンボル)を、環境省の絶滅危惧ランクで色分けしてみました。
絶滅危惧ⅠA類(CR)は赤色
絶滅危惧ⅠB類(EN)はオレンジ色
絶滅危惧Ⅱ類(VU)は黄色
準絶滅危惧(NT)は薄い黄色
非レッドリスト種(NC)は青色
絶滅危惧ランクが高い種ほど(散布図の左下に位置しており)、現状の絶滅危惧のランク付けが大まかには妥当なことがわかります。
しかし、絶滅危惧ランクの低いカテゴリーにも個体数の少ない種があり、非レッドリスト種(青色の種)にすら、個体数が少ない希少種が数多くあることがわかります。
同時に、個体数や分布面積が大きな樹木種が絶滅危惧種としてリストされているケースも少なくありません。
絶滅危惧の種のランク付けが、実際の種の希少性を反映していないことを示しています。
つまり、環境省の国レベルのレッドリストにも、経験的な知見に関係したバイアスがあり、絶滅危惧種のリスト化やランク付けが十分でないことがわかります。
いずれにしても、生物多様性ビッグデータを活用すれば、従来のレッドリスト事業を検証できて、科学的根拠に基づいて、絶滅危惧種のリスト化とランク付けを改善する手だてを与えてくれそうです。
このような分析結果を元にすれば、専門家の経験的知見を、今まで以上に効果的に活用することが可能になるはずです。
注)本記事の結果の一部は、以下の論文が元になっています。
Keiichi Fukaya, Buntarou Kusumoto, Takayuki Shiono, Junichi Fujinuma, Yasuhiro Kubota (2018) Macroscale estimates of species abundance reveal evolutionary drivers of biodiversity.
https://www.biorxiv.org/content/10.1101/426379v1.abstract